Data Miner is the most powerful web scraping tool for professional data miners
Newly released version 5.7!
Add to Chrome It's freeData Miner is a Google Chrome Extension and Edge Browser Extension that helps you crawl and scrape data from web pages and into a CSV file or Excel spreadsheet.
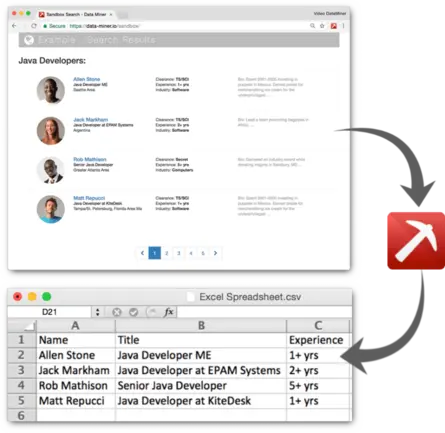
Data Miner is a Google Chrome Extension and Edge Browser Extension that helps you crawl and scrape data from web pages and into a CSV file or Excel spreadsheet.
An Easy to Use tool to Automate Data Extraction
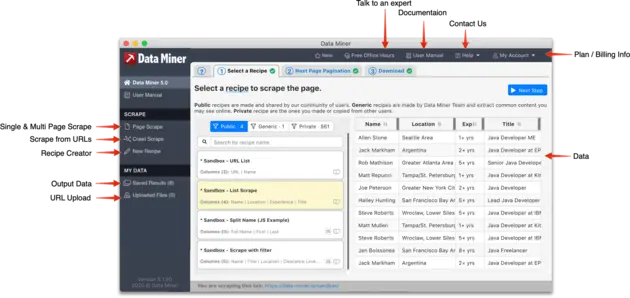
Intuitive User Interface and workflow
Data Miner has an intuitive UI to help you execute advance data extraction and web crawling.
With just a few clicks you can run any of the over 60,000 data extraction rules in the tool or create your own customized extraction rules to get only the data you need from a webpage.
Single page or
multi-page
automated scraping
Data Miner can scrape single page or crawl a site and extract data from multiple pages such as search results, product and prices, contacts information, emails, phone numbers and more. Then Data Miner converts the data scraped into a clean CSV or Microsoft Excel file format for your to download.
Data Miner comes with a rich set of features that help you extract any text on a page that you see in your browser. It can automatically click on button and links and follow sub pages and open up pop ups and scrape data from them.
New features in Data Miner 5.0
Quick and Simple Scraping
Scrape with one click.
Use
50,000+
free pre-made queries made for
15,000+
popular websites.
Streamlined workflow
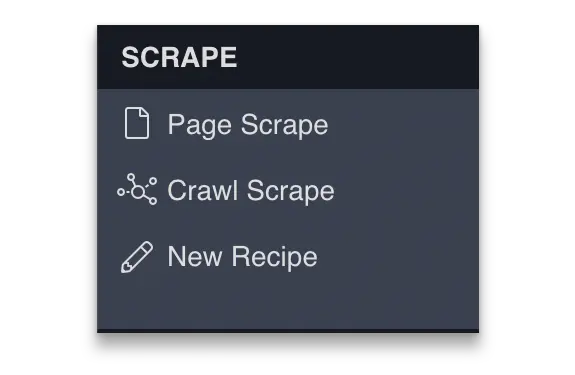
Crawl URLs, perform pagination, and scrape a single page all in one place.
No coding Required
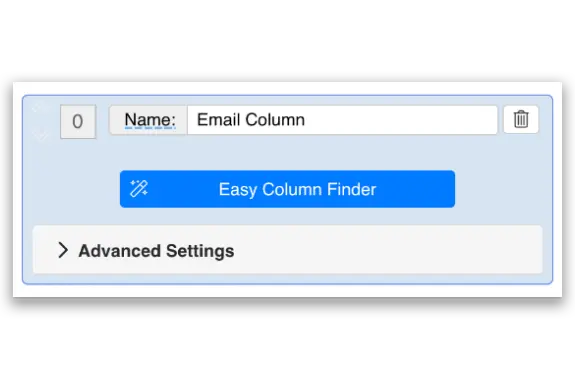
The new Easy Finder tool helps you find CSS selectors and create your own custom recipes
Secure Web crawling and Scraping
Safe and Secure to use
Data Miner behaves as if you were clicking on the page yourself in your own browser.
Scrape Without Worry

Data Miner is not a Bot.
You will not get blocked.
Keep Your Data Private

Data Miner never sells your data.
Data Miner never shares your data.
Data Miner is the most powerful scraper around

One Click Scraping
Use one of 50,000 publicly available extraction queries to extract data with one click.

Custom Scraping
Make custom extraction queries to scrape any data from any site.
Automate Scrapes
Run bulk scrape jobs base off a list of URLs.

Fast Table Scrapes
Extract basic table data
with right clicking on the page.

Pagination
Automatically click to the next page and scrape using Auto Pagination.

Form Filling Automation
Data Miner can automatically fill forms for you using a pre-filled CSV.
Watch How Data Miner works
See how easily you can convert a page to CSV
An Outstanding Support Team Helping You at Every Step

We are here to help you succeed
We live and work in Seattle, Washington, USA. You may even know a few of us like Ben, David, Ken and Zach. We are working around-the-clock to help answer support emails, share information on social media and create recipes.
You can contact us by email , phone and more!
(206) 900-8070